SongGeneration
综合介绍
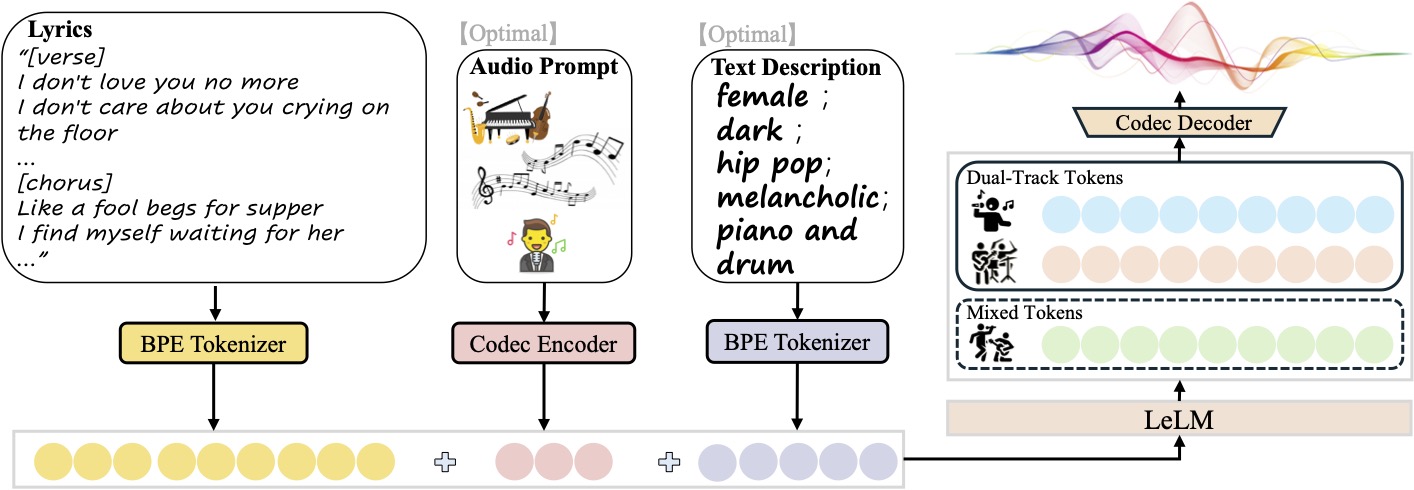
SongGeneration是由腾讯AI Lab发布的一个开源项目,其核心是一个名为LeVo的先进模型。这个项目能让用户通过文本指令,创造出包含人声和伴奏的高质量完整歌曲。它的技术基础是一个大型语言模型(LeLM)和一个音乐编解码器。该模型可以同时处理两种数据:一种是混合了人声和伴奏的“混合音轨”,用于确保两者之间的和谐;另一种是分开了的人声和伴奏“双轨音轨”,用于保证各自的音质。通过这种方式,SongGeneration生成的歌曲不仅在质量上超越了许多现有的开源音乐生成模型,甚至可以和业界顶尖的商业系统相媲美。该项目同时支持中文和英文歌词输入,并且可以独立生成纯音乐(伴奏)或清唱人声。
功能列表
- 完整歌曲生成: 输入歌词、歌曲结构和描述,模型可以自动生成包含人声和伴奏的完整歌曲。
- 纯音乐生成: 用户可以选择只生成无人声的背景音乐(BGM)。
- 清唱人声生成: 用户可以选择只生成无伴奏的清唱(a cappella)人声。
- 多语言支持: 支持中文和英文两种语言的歌词输入。
- 风格自定义: 用户可以通过文本描述(如性别、音色、曲风、情感、乐器、BPM)来精确控制生成音乐的风格。
- 音频风格迁移: 支持上传一段10秒的参考音频,模型会学习其风格来生成新的歌曲,实现风格上的模仿。
- 结构化编排: 用户可以通过特定的结构标签(如
[verse]、[chorus]、[intro-short])来定义歌曲的段落和编排。 - 低显存模式: 提供了专门为显存小于30GB的设备设计的低内存消耗运行模式。
- 多种部署方式: 支持通过
pip命令行、Docker容器以及在Windows平台集成ComfyUI等多种方式进行安装和使用。 - Web用户界面: 项目内置了一个基于Gradio的Web UI,让不熟悉命令行的用户也能轻松上手。
使用帮助
SongGeneration的安装和使用流程清晰,用户可以根据自己的技术背景选择最适合的方式。无论是开发者还是普通爱好者,都能通过以下步骤开始创作自己的AI歌曲。
环境准备和安装
在开始之前,请确保你的系统环境满足以下基本要求:Python版本需为3.8.12或更高,CUDA版本需为11.8或更高。
1. 从零开始安装 (适合开发者)
这是最常规的安装方式,通过pip包管理器来安装所需的依赖。
第一步,克隆或下载项目代码到本地,然后进入项目根目录。打开你的终端,运行以下命令来安装主要的Python依赖包:
pip install -r requirements.txt
pip install -r requirements_nodeps.txt --no-deps
第二步,安装flash-attention库。这是一个用于提升模型运行效率的关键组件。你需要根据自己的Python和CUDA版本选择对应的预编译包。例如,如果你的环境是Python 3.10和CUDA 12.0,则运行:
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
请访问flash-attention的发布页面,找到与你的环境完全匹配的版本进行安装。
2. 使用Docker安装 (适合希望环境隔离的用户)
如果你熟悉Docker,可以使用官方提供的镜像来快速搭建一个预配置好的运行环境,避免本地环境污染和依赖冲突。
docker pull juhayna/song-generation-levo:hf0613
docker run -it --gpus all --network=host juhayna/song-generation-levo:hf0613 /bin/bash
这个命令会自动拉取镜像并启动一个容器,容器内已经包含了所有必需的软件和依赖。
3. Windows图形化部署 (适合非技术用户)
对于Windows用户,社区也提供了更友好的安装方式:
- ComfyUI 插件: 你可以在ComfyUI中通过插件
ComfyUI_SongGeneration来使用。 - 一键安装包: 社区中有用户制作了Windows一键安装包,可以从Bilibili等视频平台找到相关资源和教程。
模型和文件准备
无论使用哪种安装方式,你都需要从Hugging Face下载模型的权重文件和配置文件。
- 下载模型文件: 访问模型的Hugging Face页面,下载
ckpt和third_party两个文件夹。 - 放置文件: 将下载的
ckpt和third_party文件夹移动到你本地SongGeneration项目的根目录下。ckpt文件夹中应包含模型的.ckpt(权重)和.yaml(配置)文件。
生成你的第一首歌曲
准备工作就绪后,就可以开始生成歌曲了。核心操作是通过运行脚本来完成的。
1. 准备输入文件
你需要创建一个.jsonl格式的文件来告诉模型你要生成什么样的歌曲。文件中的每一行都是一个独立的JSON对象,代表一首歌曲的生成请求。
一个JSON对象包含以下字段:
idx: 歌曲的唯一标识,生成的音频文件名会使用这个名字。gt_lyric: 歌词和歌曲结构。格式非常重要,必须是“[结构标签] 歌词内容”的形式,不同段落用分号;隔开。descriptions(可选): 描述歌曲风格的文本。例如:“female, pop, energetic, piano and drums, the bpm is 120”。prompt_audio_path(可选): 提供一个10秒参考音频的路径,模型会模仿其风格。auto_prompt_audio_type(可选): 如果不提供参考音频,可以指定一个风格(如 'Pop', 'Rock'),让模型自动从内置库中挑选参考。
示例 lyrics.jsonl 文件内容:
{"idx": "my_first_song", "gt_lyric": "[intro-short] ; [verse] 我们曾经的回忆. 像褪色的电影. 你的眼泪我无法抹去. ; [chorus] 心碎成片片落地. 我还在原地等你. 像个傻瓜一样地爱你. ; [outro-short]", "descriptions": "male, pop, sad, piano, the bpm is 80"}
2. 运行生成命令
打开终端,使用以下命令启动生成过程。
- 标准模式 (适用于显存 > 30GB):
sh generate.sh [ckpt_path] [lyrics.jsonl_path] [output_path] [gen_type]
- 低显存模式 (适用于显存 < 30GB):
sh generate_lowmem.sh [ckpt_path] [lyrics.jsonl_path] [output_path] [gen_type]
命令参数说明:
ckpt_path: 模型权重和配置文件的存放路径,例如ckpt/songgeneration_base。lyrics.jsonl_path: 你创建的输入文件路径,例如sample/lyrics.jsonl。output_path: 生成音频的保存路径,例如sample/output。gen_type(可选): 生成类型。bgm表示纯音乐,vocal表示清唱,留空则生成完整歌曲。
完整示例命令:
sh generate_lowmem.sh ckpt/songgeneration_base sample/lyrics.jsonl sample/output
3. 使用Gradio Web UI
如果你不想使用命令行,可以启动项目自带的图形界面。
sh tools/gradio/run.sh [ckpt_path]
运行后,终端会提供一个本地网址(通常是 http://127.0.0.1:7860),在浏览器中打开即可看到一个友好的操作界面。你可以在网页上直接输入歌词、选择风格并生成歌曲。
应用场景
- 音乐制作人和独立艺术家音乐创作者可以使用SongGeneration快速生成歌曲的伴奏或人声小样,作为创作的起点和灵感来源。当遇到创作瓶颈时,可以输入简单的旋律构思或歌词,让AI生成多个不同风格的版本,从中挑选满意的部分进行深化。
- 内容创作者和视频博主为短视频、Vlog或播客节目制作独一无二的原创背景音乐。创作者只需根据视频的主题(如“悲伤”、“旅行”、“科技感”)输入描述,即可生成符合氛围的BGM,避免了使用罐头音乐带来的版权风险和内容同质化问题。
- 游戏开发者独立游戏开发者或小型团队可以利用它低成本地为游戏制作各种场景音乐。无论是需要激昂的战斗音乐、宁静的场景背景音,还是特定角色的主题曲,都可以通过调整描述参数来快速生成,极大地提高了配乐的制作效率。
- AI音乐研究与教育对于AI和音乐专业的学生及研究人员,SongGeneration作为一个开源项目,提供了绝佳的学习和研究平台。他们可以深入研究其模型架构(LeLM)、数据处理流程和多模态对齐技术,甚至在其基础上进行二次开发和实验,探索AI音乐生成的更多可能性。
QA
- 这个模型生成的音乐可以商用吗?根据项目在GitHub上的
LICENSE文件,该代码和模型权重遵循特定的开源协议。在使用前,请仔细阅读并遵守该文件的条款,以确定其是否允许用于商业用途。通常,开源项目会有不同的许可限制。 - 我必须严格遵守输入的歌词格式吗?是的,必须严格遵守。模型的训练数据依赖于
[结构标签] 歌词.的格式来理解歌曲的段落和节奏。不正确的格式,如缺少结构标签、段落间未使用分号;或句子结尾未使用句号.,都可能导致生成失败或产出质量低下的结果。 - 如果我同时提供了描述文本和参考音频,会发生什么?官方建议不要同时提供这两者。如果描述(
descriptions)和参考音频(prompt_audio_path)的信息存在冲突(例如,描述为“摇滚”,但参考音频为“爵士乐”),模型可能无法准确理解你的意图,导致生成效果下降。优先使用其中一种方式来指导模型。 - 生成一首歌曲需要多长时间?生成时间取决于你的硬件配置(主要是GPU性能)、歌曲的长度以及所选择的模式。在配置较好的GPU上,生成一首标准长度的歌曲通常需要几分钟。使用
generate_lowmem.sh低显存脚本会比标准模式稍慢一些。 - 模型支持哪些乐器和曲风?模型支持的词汇是开放的,但为了获得最稳定和可靠的效果,建议使用官方在
sample/description/文件夹中提供的预定义标签。这些标签涵盖了常见的曲风(如流行、摇滚、爵士)、情感(如悲伤、浪漫、活力)、乐器(如钢琴、吉他、鼓)等。